When a musician performs, they're doing something that goes far beyond pressing the right keys in the right order. They're making thousands of tiny decisions all intuitively, such as pressing this key harder for emphasis, letting that one barely whisper, or slowly building toward a climax. These choices are what make music feel human, what makes it feel like art. But they're also almost impossible to write down or tell to someone.
I spent my bachelor's thesis trying to solve this question: can an AI learn to make those same decisions? I did this by taking piano as an analogy, partly because I play the piano myself and partly because it's easy to put in a digital format.

The Difference Between Playing and Performing
Imagine you had a player piano that read sheet music perfectly. They can play every note at exactly the right time, and at exactly the right length. It would sound technically correct, but at the same time completely wrong. Why is that?
What's missing is expression. With one element being the loudness of each individual note, or more idiomatically called: dynamics. The same reason that someone speaking monotone is boring, is exactly the reason monotone music is boring. A good pianist will make each note louder or softer based on the emotion they want to bring to the audience. Sometimes they even change dynamics within the same chord, one finger pressing very softly while another strikes hard.
In digital music, this loudness-per-note is called velocity. Think of it like how hard the key is pressed. A high velocity is associated with a loud note. A low velocity is soft and delicate. This is exactly the key I needed for predicting some part of this expression that pianists do so well. It's a single number that I could predict based on existing data of pieces played by musicians.
Teaching AI the Way You'd Teach a Language
The technique I used is borrowed from how AI learns a language, the result of which you have already interacted with. Translation tools, and in some way ChatGPT and similar tools learned to understand language partly by playing a filling-in-the-blanks game: take a sentence, hide a few random words, and ask the model to guess what's missing. Do this billions of times and the model gradually builds a real understanding of how words relate to each other.
 A visual representation of how it works.
A visual representation of how it works.
I did the same thing, but with music instead of words.
I fed the AI hundreds of hours of professional piano recordings. This was done as a digital MIDI file, which gives you every note, its pitch, exactly how long it was pressed, and how loud it was. Then I hid some of the loudness values and asked the model to guess them, using everything around them as context. The training data came from real performances from good musicians, it included 172 hours of amazing pianists playing everything from Beethoven to Ravel, recorded on a special piano that could make these MIDI files.
And the results?
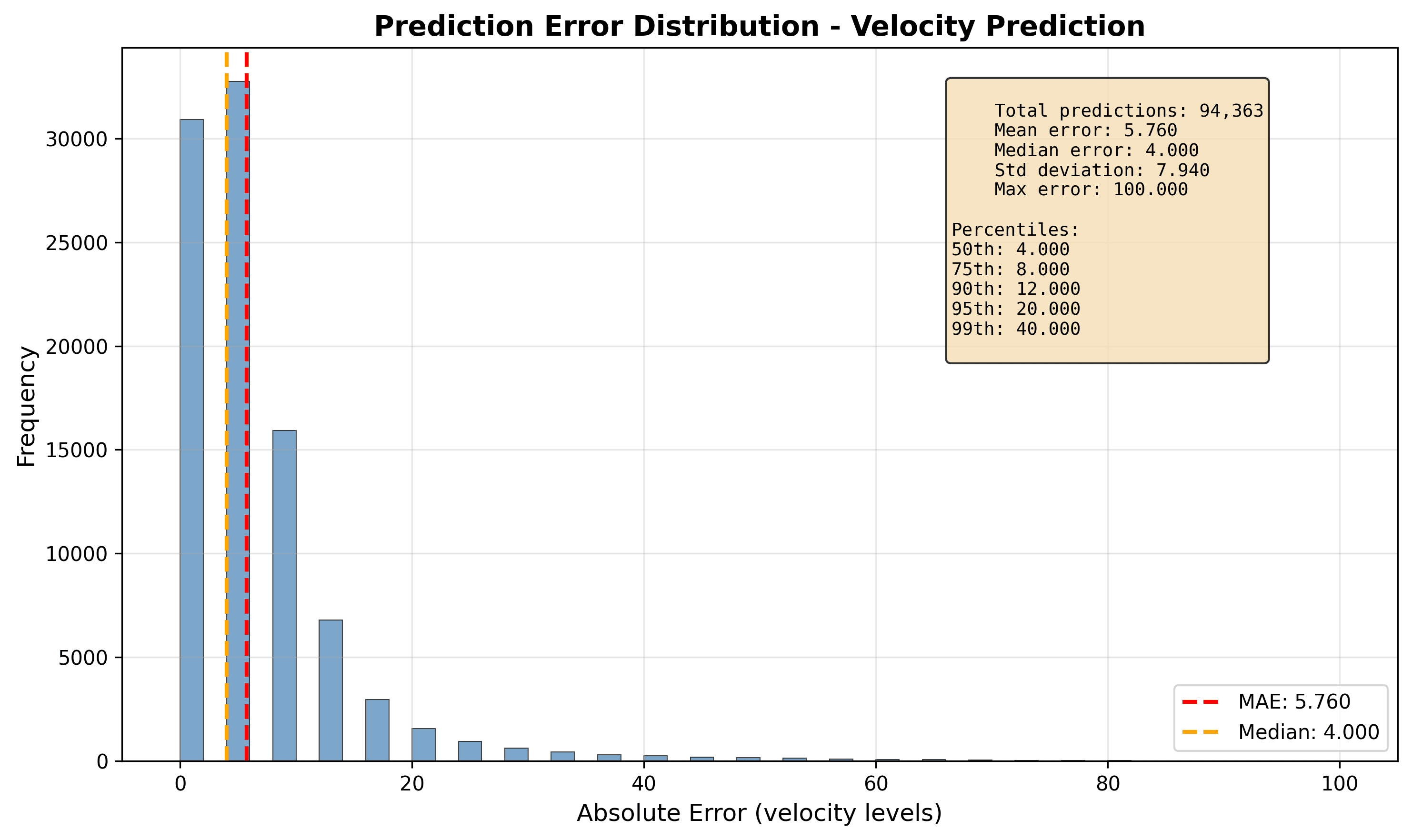
The AI could choose from 32 possible loudness levels for each note. If the AI would random guess, it would get it right about 3% of the time. My model got it exactly right about 33% of the time, but 68% of the time, it was within one level of the correct answer.
That one-level margin matters is still very good because the average human ear can't actually hear the difference between two loudness levels just one apart from each other. So nearly two-thirds of the time, the model's answer was very close to the correct loudness and hard to hear as wrong for an average listener.
The average mistake was also small, it was about 5.7 units off on a scale of 0 to 127. That's roughly the difference between playing a note normally and playing it very slightly louder.
But What Was the AI Actually Looking At?
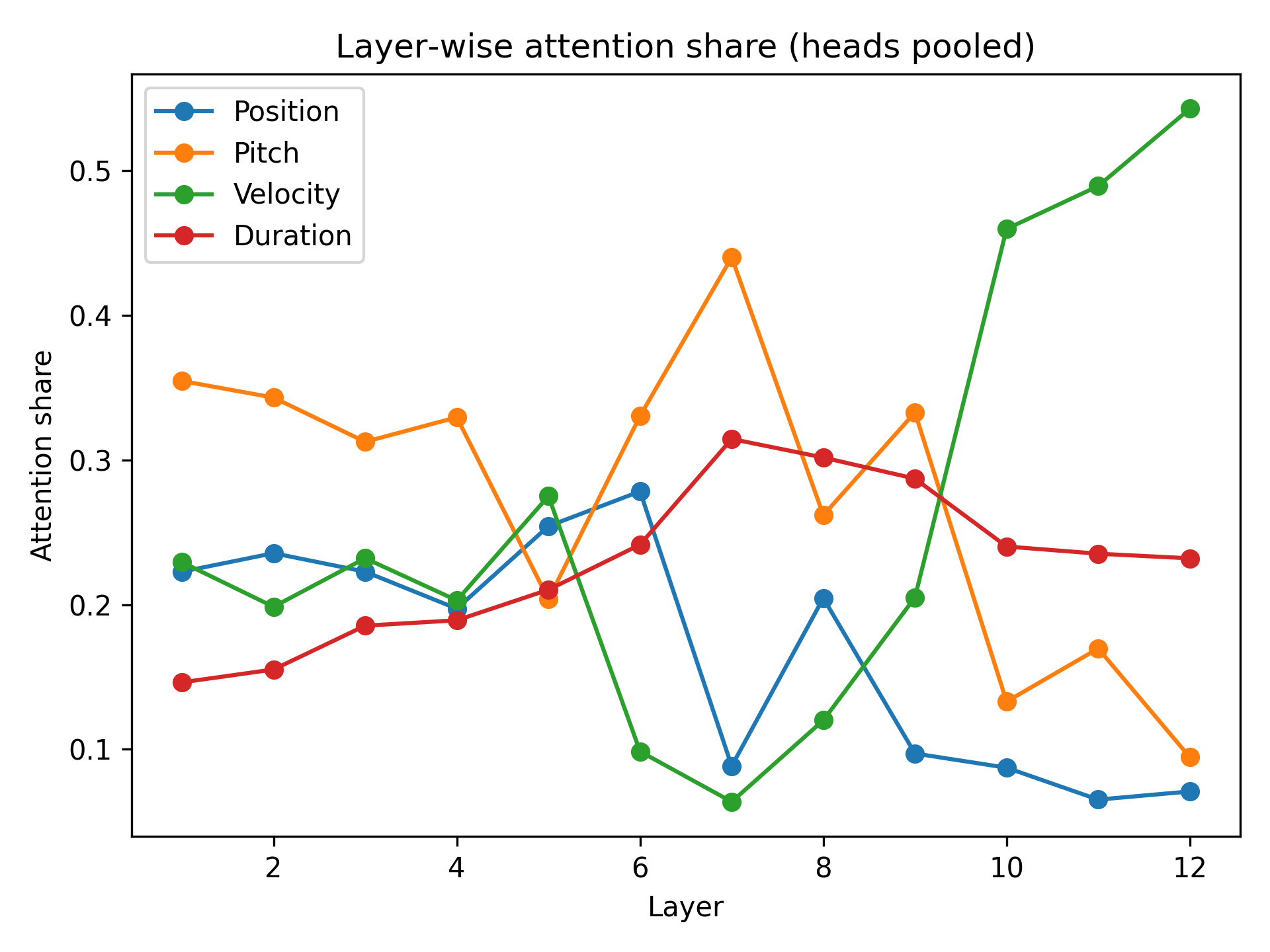
The second part of my thesis tried to look inside the AI that I created. I tried to see what it was actually taking into account when predicting a loudness value.
AI models like this the one I built process information in layers. It goes through multiple stages and refining their answer in each. Think of each layer as having their own expertise. I then tracked what each layer was focusing on and tried to find a pattern in it.
- In the early stages, the AI mostly looked at pitch, this is which notes were being played; is it an A, an B, a D flat etc. This makes sense, the actual note is one of the most basic things that forms it loudness.
- In the final layers, the AI looked at the loudness of surrounding notes, so it was saying "what are the notes around this one doing?" This is exactly what real musicians do instinctively: they decide the loudness of each note partly based on what came before and what comes next.
- Timing here mattered least. The AI mostly ignored rhythmic position when deciding on loudness.
What My AI Can't Do
With this thesis I only really focused on one way of looking at expression. In most musical performances timing is also a very important factor. The musician plays notes slightly early or late for effect, holding an important chord a bitt longer, then going a bit faster again through a passage to build tension. Due to time constraints I didn't add this to the model yet.
The AI also never had the output evaluated by an actual musician. The numbers look good in theory, but whether the result sounds right to a trained pianist is something I didn't test yet.
And it only knows classical piano, because that is the dataset I used. If I ask it to predict the loudness of a jazz improvisation it would probably do bad.
So, Did it Succeed?
My AI did not really recreate expression. But it can learn something real about how humans express it.
The main point of my thesis wasn't really the accuracy I got out of it. What I was most interested in was what the AI chose to focus on. Trained entirely on data, with no understanding of music theory built that I gave it, it independently figured out that the pitch of a note and the loudness of the notes next to it are the most important clues for deciding how loud to play something. That's actually musically sensible. And the interesting thing is that one told it that, it worked it out entirely on its own.
Expression in music has always felt like a purely human thing. We think it is intuitive, emotional, and impossible to write down. This project suggests there are patterns underneath it that a machine can begin to learn. It won't ever replicate the soul of a performance, but maybe the grammar of one.
Based on my bachelor's thesis in Computer Science, done at Universiteit van Amsterdam, July 2025
Supervisor: Christoph Finkensiep